I have lots of things to do, but I’ve suddenly been struck by inspiration, and since the well-known work-avoidance mechanism has kicked in, I’m going to write down my thoughts on test-time compute, shared decoders, and reasoning. Here we go, a theoretical and lengthy piece is coming.
One of the things I love about LLMs is that they handle multiple tasks with a single loss and a single branch. That is, instead of a shared encoder + separate decoders for each task like in U-net models, there’s just a transformer decoder. As far as I know, this comes from T5 models where we model all NLP tasks as text-to-text. We’ll get back to LLMs in a bit, but let’s take a look at the vision side for now.
I don’t think there’s an equivalent of this in vision, for example, how would you combine segmentation and classification tasks? At the very least, the last layers would have to be different. However, there’s a model that comes very, very close to combining these, and the model’s developers are inspired by the human brain. The model is called BU-TD. Let’s start with the inspiration part. These folks are saying, ‘segmenting anything and everything at once’ is not the right approach; the human brain doesn’t work that way.
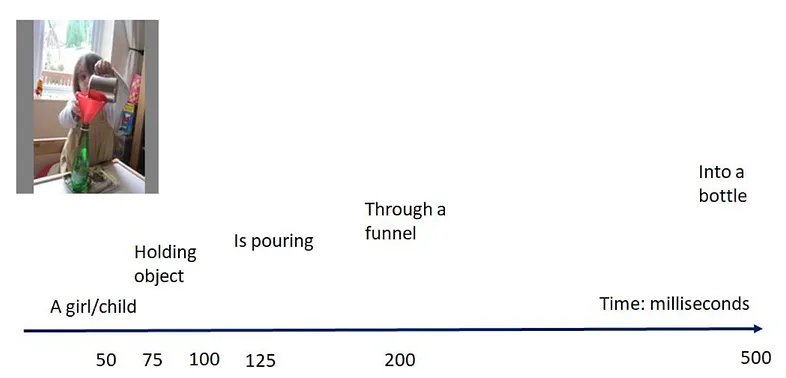
For example, the longer you look at the image above, the more details emerge; the brain doesn’t grasp the entire image with all its details at once. So why are we trying to make models do this? This is where BU-TD comes into play.
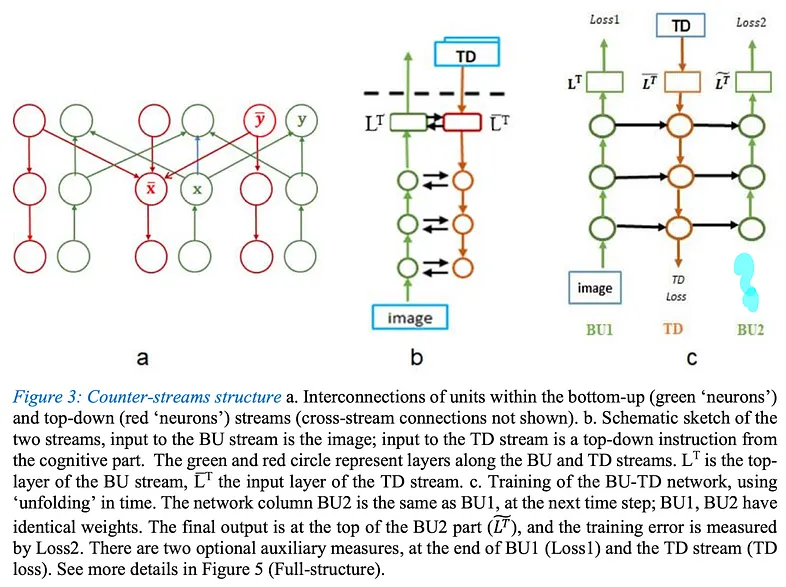
Again, in this model inspired by the human brain, first an encoder processes the image, and the decoder takes the vector coming from the encoder and additionally receives a task and argument vector. For example,

We tell the model to look at the image, task: find hairstyle, argument: bob. Afterwards, the decoder can optionally output the segmentation of Bob’s hair, but it may not; that part is a bit vague. By feeding the decoder’s result back into the encoder, we get the result corresponding to that style, and so on.
The nice thing about this system is that it first uses the weights in the decoder to the fullest, making it a parameter-efficient model. Secondly, since each task, argument, etc., is decoupled, the system learns concepts better. For example, during training, brother Bob is always bald, so Bob’s hairstyle value is always bald during training. However, since the model learns what short hair and long hair are from other examples independently of the person, it can detect this during testing if Bob comes to Turkey and gets hair implants. Thanks to this, the model learns much better with much less data.
Now we come back to LLMs. We are actually applying the TD part of this model, that is, using a single decoder for each task, in LLMs since the T5 models, especially in PrefixLM models, and when image tokens and (I think) the question are processed with self-attention, the TD logic is formed.
The second part is that when people look at a picture, we extract the details, relationships, etc. over time; all the details don’t come at a single glance, right? Well, this part actually corresponds to the concept we call test-time compute. For example, as we look at the image on the left below, the details on the right emerge.
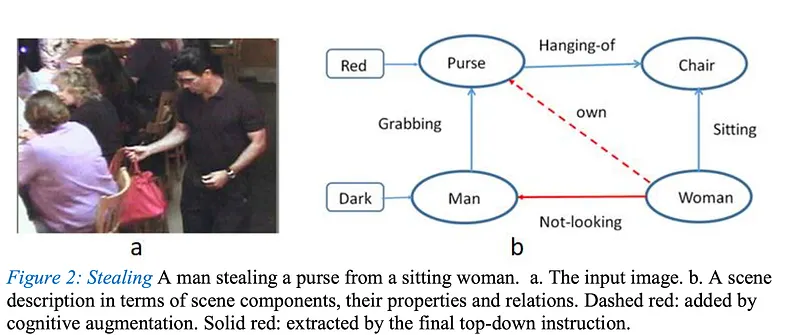
Based on what we’ve learned up to this point, trying to process everything at once is not logical. Learning the relationships one by one during training and processing the image over time using more compute/time during testing is an effective solution in terms of both the number of parameters and learning more with less data. Our next problem is this: We don’t want to process the image all at once, okay, but we also don’t want to process the entire image; we want to process as much as necessary for the information we are interested in to save time and money. This is where reasoning comes into play. What does a good LLM model do in terms of reasoning? It divides the question we ask into the necessary parts and solves the parts step by step, and stops when it reaches the result. By doing this, we have the following system:
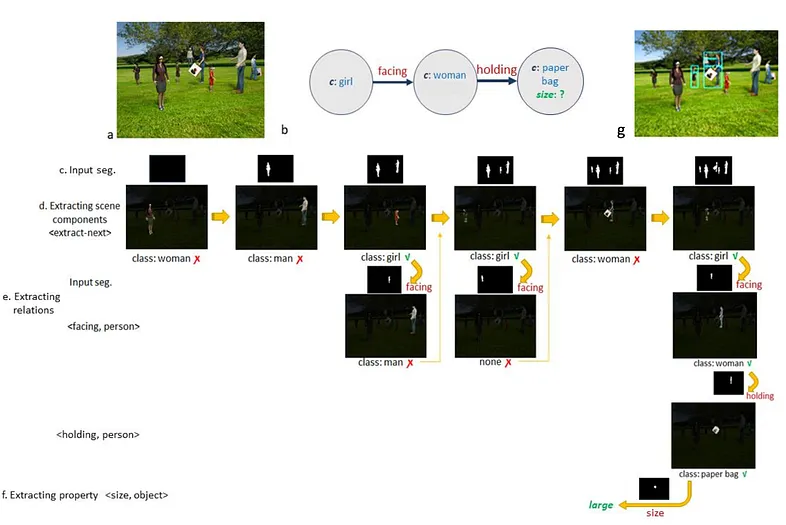
I’m saying that if I were shown a picture and asked, ‘What is the size of the bag of the woman holding the bag that the girl is looking at?’, my brain would process the image in a similar way and wouldn’t look for more details.
I think the BU-TD model itself is very limited in terms of input and output ranges but the main idea is still strong and I believe VLMs are very close to implementing this idea into the AI models.
That’s it, I couldn’t come to a conclusion with the text. These things suddenly came to my mind while reading a very unrelated article, I thought I’d write them down. Good luck and thanks for reading up to this point!